余化鹏老师 GPU 服务器升级 CUDA 事故总结复盘
问题描述
在容器内升级显卡驱动后,GPU 计算功能正常,例如 torch.cuda.is_available() = True,但执行 nvidia-smi 时却检测不到 GPU。这种现象不会影响 PyTorch 使用显卡加速,但会影响其他依赖 NVML(如 Ollama)的程序,提示警告或功能缺失。
解决思路:明确 nvidia-smi 与 PyTorch 调用 GPU 的底层逻辑
GPU 虚拟化方案与依赖关系
宿主机访问 GPU 的路径如下:
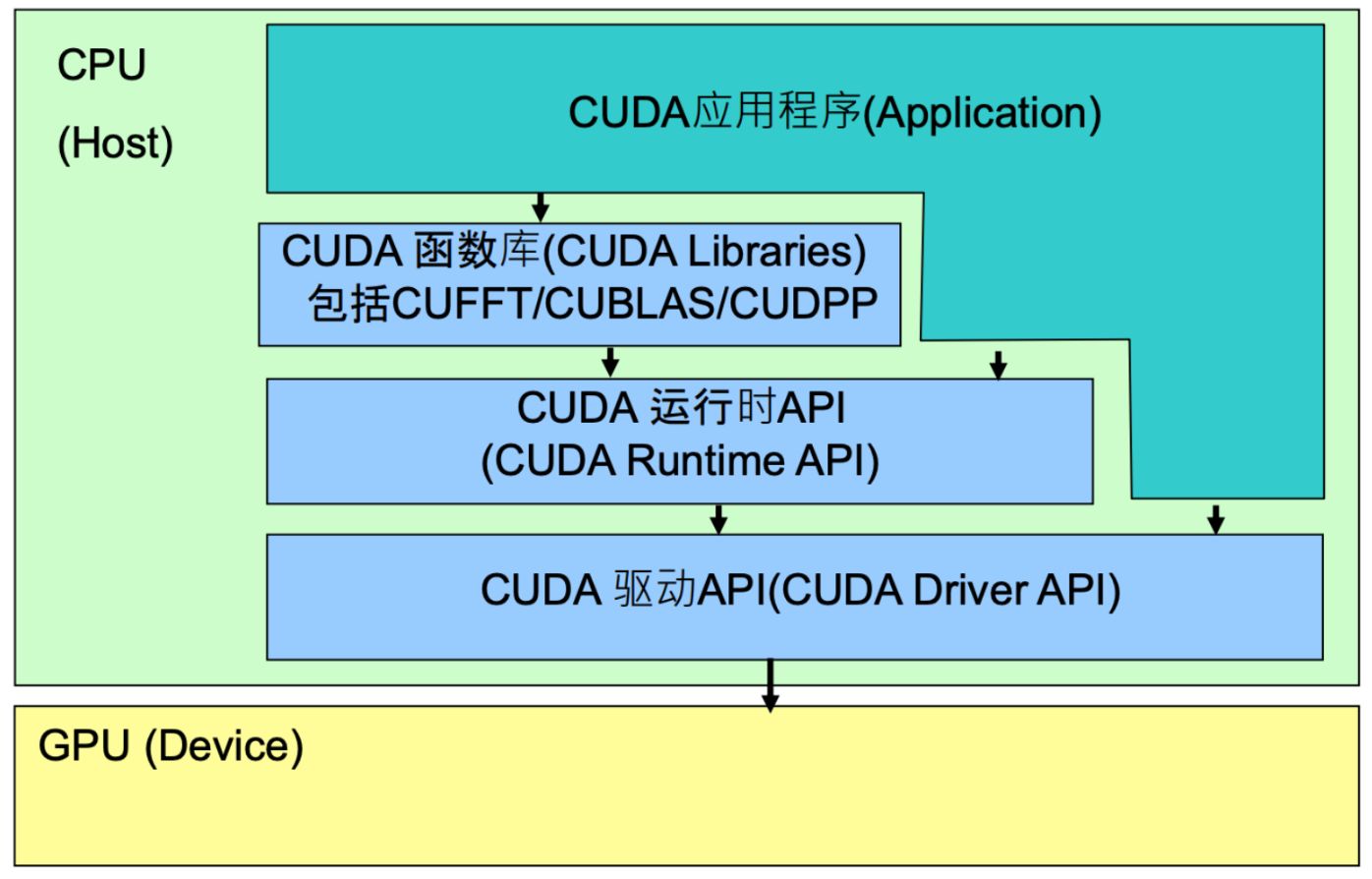
- CUDA Driver API:最底层的 GPU 控制接口,性能最优,但开发复杂,通常不直接使用。
- CUDA Runtime API:对 Driver API 的封装,简化了调用逻辑,是大多数程序的首选。
- CUDA Libraries:对 Runtime API 的进一步封装,包含如 cuDNN、cuBLAS 等高性能库。
容器内如何实现 CUDA 支持?
NVIDIA Docker 实现方式
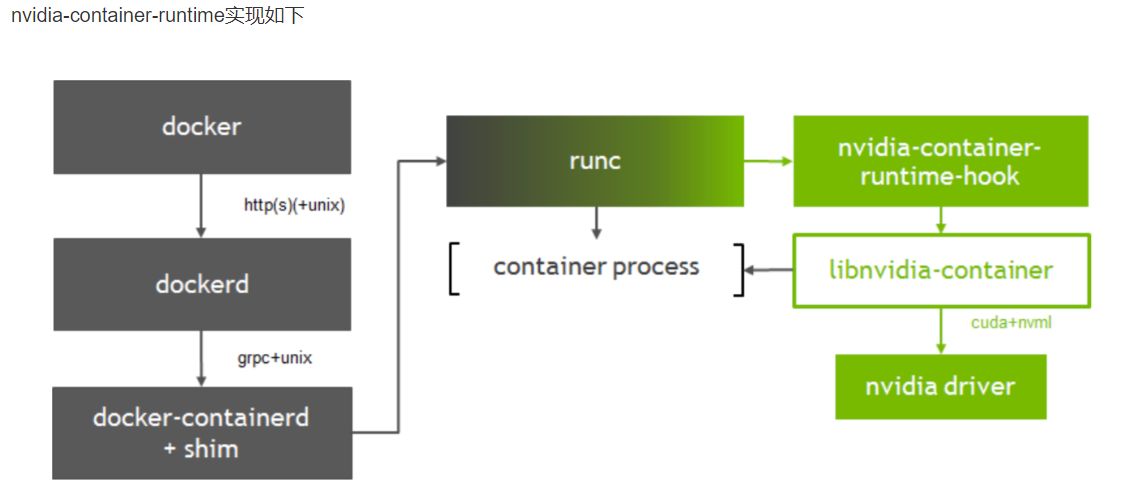
NVIDIA Docker 修改了 Docker 的 Runtime,通过挂载方式将宿主机的 GPU 设备文件 和 CUDA Driver 映射进容器:
- 包括
/dev/nvidiactl、/dev/nvidia-uvm、/dev/nvidia-uvm-tools、/dev/nvidia-modeset - Driver 库文件同样通过 Runtime Hook 注入容器环境

注意:CUDA Driver API 必须存在于容器中,且版本需与宿主机保持一致,否则 NVML(nvidia-smi)将无法正常工作。
我的理解与猜测
挂载设备后,容器内各组件之间通信路径大致如下:

关于直通模式(PCIe Passthrough):
- 虚拟机/容器独占物理 GPU,宿主机仍需加载
vfio-pci等模块 nvidia-smi本质上依赖 NVML,即宿主机驱动接口的转发- 所以:容器内的 NVML 库版本必须严格等于宿主机 CUDA 驱动版本
实际解决方案回顾
检查与发现
- 宿主机 CUDA 驱动版本为 550.144.03
- 容器内 CUDA 驱动版本为 570.86
- 版本不一致 → 导致
nvidia-smi报错,但 PyTorch 不受影响
尝试解决:
-
尝试使用软链接修复:
ln -sf /usr/lib/x86_64-linux-gnu/libnvidia-ml.so.550.144.03 /usr/lib/x86_64-linux-gnu/libnvidia-ml.so→ 无效,说明不仅需要库文件链接,还涉及驱动内部状态与运行时兼容问题
最终成功方法:
- 回退安装与宿主机一致的 CUDA Driver 550.144.03
- 同步安装兼容版本的 CUDA Toolkit 12.4
- 手动检查
/usr/lib/x86_64-linux-gnu/下的所有 NVIDIA 驱动组件 - 使用
.run或.sh脚本重新安装 toolkit(推荐 NVIDIA 官网原版脚本) - 无须重启容器,
nvcc、nvidia-smi均正常,PyTorch 也无报错
总结与建议
什么是 NVML?
The NVIDIA Management Library (NVML) is a C-based programmatic interface for monitoring and managing various states within NVIDIA Tesla™ GPUs. It is intended to be a platform for building 3rd party applications, and is also the underlying library for the NVIDIA-supported nvidia-smi tool. NVML is thread-safe so it is safe to make simultaneous NVML calls from multiple threads.
- NVML 是 线程安全的
- 所有依赖 GPU 管理状态(温度、显存、使用率等)查询的工具,如 Ollama,都依赖它
实践经验总结:
-
如果你在 容器内无法使用
nvidia-smi,但 PyTorch 可用,多数情况是 CUDA Driver 版本不一致。 -
容器中可以单独安装或更新:
- CUDA Driver(必须与宿主机一致)
- CUDA Toolkit(版本可以不同,但建议查阅官方对应关系)
🔗 推荐链接:CUDA Toolkit 与 Driver 版本对应关系
⚠️ 安装 CUDA Toolkit 时,建议使用官网下载的
.sh安装脚本,若出现异常,不要尝试奇技淫巧修复,请重新安装。